On this page I have logged some common queries, objections, discussion points, and
errata sent in by readers of
Prime Obsession.
If you'd like to contribute something, send it to my gmail address (which you can find on
my home
page) with a subject line beginning with PRIME OBSESSION.
In what follows, when I want to refer to text in the book, I give the page number followed by a one-digit decimal to
indicate
placement in the page. So [176.3] means about 30 percent of the way down page 173.
Contents of this web page
* Can a Mathophobe Read Prime Obsession?
• Reader's point: I am a total mathophobe. I hate equations and formulas and stuff. Can I get anything out of your book?
• Author's reply: Ah, "the fear of all sums"! Well, I hope mathophobes (I have a feeling that should actually be "mathephobes," but Merriam-Webster's Third is no help here**) will be able to get something out of my book, if not to the value of the full purchase price. I suggest you try the following plan.
- Read the Prologue.
- Read Chapter 2.
- Read the Epilogue.
- Browse the Endnotes, looking for interesting non-mathematical snippets.
- Read Chapter 22.
- Start in on the rest of the even-numbered chapters (4, 6, 8, 10,...) and get as far as you can.
- If you make it all the way to Chapter 20, try the odd-numbered chapters. Please.
———————————————————
** Though one of my readers, Evan McElravy, was:
Mr. Derbyshire: I am myself a fair mathephobe. I do, however, know something of Greek and your hunch is correct. If you'll indulge me a moment:
There are two main noun forms in Greek for the word, (1) hê mathê, and (2) to mathêma, whose stem is mathêmat-. Both are derived from the aorist stem of the verb manthanein (math-). While this stem has no terminal vowel ("they learned" = emathon), and the final η in the first form is just an inflectional ending, in all the various other forms, like the second form above, and the few derivatives (e.g., hê mathêteia = "instruction from a teacher;" ho mathêtês = "student") there is an intermediate η (eta). The big Liddell and Scott indicates no authentic Greek compounds where math is the first element, but it seems certain that there would be an η there.
Alternatively, there is apparently an epic and Ionic form, to mathos, of hê mathêsis ("the act of learning," also "custom") that declines like to pathos, with a stem in ε (epsilon), not η, which blends with other vowels as necessary (hence "pathe-tic" but "path-ology"). Either way, we're left in the Latin alphabet with "mathephobe." Someone who is scared of numbers entirely, though, would be an arithmophobe, but I think we've had enough fun with Greek today.
[Me] Phew! And I thought math was hard!
* My Mathematica Notebooks
• Reader's point: Can you send me, or post somewhere, the Mathematica notebooks you used for your calculations and diagrams?
• Author's reply: Mostly no. The book was written in a tearing hurry over about six months. Most of the math was done on the fly, and most of the notebooks have not survived in their original form. (I mean, I either cannibalized earlier ones to make later ones, or just lost them.)
This is not actually a great loss to humanity. I am not a deep Mathematica user, and the code I developed was not particularly brilliant or imaginative. In most cases, you could re-create it yourself in a few minutes by just looking at the result diagram or calculation.
For an illustration from the Mathematica notebooks that survive on my hard drive, here is the code behind the statement on page 284 that: "I asked my math software package, Mathematica 4, to generate a random 269×269 Hermitian matrix and compute its eigenvalues."
<< Statistics`DescriptiveStatistics`
<< Statistics`ContinuousDistributions`
ndist=NormalDistribution[0,1]
n=269
re=Table[Random[ndist],{n},{n}]; im=Table[Random[ndist],{n},{n}];
herm=Table[Which[i==j,Sqrt[2]*re[[i]][[i]],i<j,re[[i]][[j]]+I*im[[i]][[j]],
i>j,re[[j]][[i]]-I*im[[j]][[i]]],{i,n},{j,n}];
ei = Sort[Re[Eigenvalues[herm]]];
Export["Hermitian 269x269 Eigenvalues.txt",ei,"List"]
There was nothing much deeper than that.
* That Card Trick
• Reader's point: In your "card trick," [3.5] are you sure about that third card going forward one-sixth of a card length? Seems to me it should be one-eighth.
• Author's reply: I am baffled by the number of people who told me this, since I included a diagram at the top of page 5 showing, as clearly as it can possibly be shown, why the correct number is one-sixth. But OK, let's try your way. We push that third card forward one-eighth of a card length. What have we got in front of the "tipping point"? (I.e. the leading edge of the main part of the deck.) Well, we've got
7/8 of the top card (because I pushed it 1/2, then 1/4, then 1/8); plus
3/8 of the second card (because I pushed it 1/4, then 1/8); plus
1/8 of the third card.
That's a total of 11/8 card lengths (7 + 3 + 1 = 11) in front of the "tipping point." Now, 3 minus 11/8 equals 13/8. So out of those three top cards, 11/8 card lengths is in front of the "tipping point," while 13/8 card lengths are behind it.
Which means that it is not a tipping point at all; we can still push a little further!
One-sixth is the correct answer.
If you are still not convinced, I can only suggest you take out a deck of cards and try it. You can easily distinguish between one-sixth and one-eighth of an ordinary card length.
When it comes to the fourth card, the math changes slightly. After you push the top four cards out a distance one-eighth, the topmost card is now entirely beyond the tipping point. Its back edge is in fact one-twenty-fourth ahead of the tipping point. To confirm that this is, in fact, the tipping point, you therefore need to take moments into consideration. Obviously the "tipping effect" of that topmost card's mass is greater the further ahead of the tipping point it is. With the top four cards pushed out 1/2 plus 1/4 plus 1/6 plus 1/8, the arithmetic to check that the tipping point is correct now goes as follows.
To the right of the tipping point we have
- Top card: mass 1 card, center of mass 13/24 to the right of the tipping point, moment 1 × 13/24 = 13/24 = 624/1152.
- 2nd card: mass 13/24, center of mass 13/48 to the right of the tipping point, moment 13/24 × 13/48 = 169/1152.
- 3rd card: mass 7/24, center of mass 7/48 to the right of the tipping point, moment 7/24 × 7/48 = 49/1152.
- 4th card: mass 1/8, center of mass 1/16 to the right of the tipping point, moment 1/8 × 1/16 = 1/128 = 9/1152.
Total clockwise moment: 851/1152.
To the left of the tipping point we have
- Top card: no contribution, it's all on the right.
- 2nd card: mass 11/24, center of mass 11/48 to the left of the tipping point, moment 11/24 × 11/48 = 121/1152.
- 3rd card: mass 17/24, center of mass 17/48 to the left of the tipping point, moment 17/24 × 17/48 = 289/1152.
- 4th card: mass 7/8, center of mass 7/16 to the left of the tipping point, moment 49/128 = 441/1152.
Total counterclockwise moment: 851/1152. Q.E.D.
* Sequence Converging to √2
• Reader's point: In Chapter 1.vii [16.5] you say: "Consider the following sequence of numbers: 1/1, 3/2, 7/5, 17/12, 41/29, 99/70, 239/169, 577/408, 1393/985, 3363/2378, … Each fraction is built from the one before by a simple rule: add top and bottom to get new bottom, add top and twice bottom to get new top. That sequence converges to the square root of 2." Why? Can you prove this?
• Author's reply: Of course I can! That simple rule turns a/b into (a+2b)/(a+b). Or, by elementary algebraic manipulation, into 1 + b/(a+b). Or, by a wee bit more manipulation, to 1 + 1/(1 + a/b). Fix that in your mind: starting from a/b, one application of the "simple rule" gets you to 1 + 1/(1 + a/b). If I call a/b "R" (for "ratio") then one application of the rule gets you from R to 1 + 1/(1 + R).
Where would two applications of the rule get you? Well, the first application gets you to 1 + 1/(1 + R), then the second of course gets you to 1 + 1/(1 + [1 + 1/(1 + R)]), or in other words, to 1 + 1/(2 + 1/(1 + R)).
A third application of the "simple rule" would then give you 1 + 1/(1 + [1 + 1/(2 + 1/(1 + R))]), or in other words:
1 + 1/(2 + 1/(2 + 1/(1 + R))).
A fourth application of the rule gives 1 + 1/(2 + 1/(2 + 1/(2 + 1/(1 + R)))). A fifth gives 1 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(1 + R))))). You can see where this is heading. A very large number of applications of that simple rule gets you from R to a number that looks like this:
1 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + … + 1/(1 + R)))))...)))))
(Mathematicians call this "a continued fraction.") Note that the size of R matters less and less as you keep iterating. If R was totally humongous, that final 2 + 1/(1 + R) would be just a teeny bit bigger than 2; if R was incredibly tiny, it would be an eentsy bit less than 3. As you proceed leftward, calculating as you go, the difference dwindles away to nothing.
But what is that thing? What, to take it off to infinity, is
1 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + …)))))?
Well, call it x, and rewrite it just slightly as
1 + 1/(1 + 1 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + …))))),
even putting in an extra parenthesis, if you like, to make things clearer:
1 + 1/(1 + [1 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + 1/(2 + …))))])
Then if you look closely at it, you will see that the following thing is true:
x = 1 + 1/(1 + x),
which, if you rearrange it, says that x 2 = 2.
I repeat: this is true no matter what a/b you start with. In Prime Obsession I started with a = 1, b = 1, just for simplicity.
(The other sequences in this section are a bit harder!)
* Sequence Converging to e
• Reader's point: In Chapter 1.vii [16.8] you say: "Here is yet another [i.e. another sequence]: 11, (1½)2, (1⅓)3, (1¼)4, … If you work them out, these come to 1, 2¼, …" Since the rule is (1 + 1/n)n, shouldn't the first numbers there be 21 and 2?
• Author's reply: Of course they should. Thank you!
* The Randomness of Prime Distribution
• Reader's point: You say there are only eight primes in the last hundred-block before a million, that is, from 999,901 to 1,000,000; and that there are only four in the last hundred-block below a trillion, from 999,999,999,901 to 1,000,000,000,000. Seems to me there must be hundred-blocks between a million and a trillion that have more than eight and/or less than four (or exactly eight or four), i.e., there are lots more than four hundred-blocks between a million and a trillion; the eight can't decrease only to four (unless, say, lots have seven, then lots have six, then lots have five).
• Author's reply: One thing I regret is not having put more emphasis on the randomness of the distribution of primes the way they sometimes clump together, sometimes spread apart, apparently unpredictably. That's what comes into play here.
Consider that first hundred-block I mentioned, for instance, the one from 999,901 to 1,000,000. There are, as I said, 8 primes in that block. In the previous hundred-block, however — the one from 999,801 to 999,900 — there are only 4 primes. Stepping back through the hundred-blocks prior to that, the numbers of primes in each block are 6, 8, 6, 6, 7, 6, 5, 8, 10, … Stepping forward (that is, starting with the hundred-block from 1,000,001 to 1,000,100), the number of primes in each hundred-block is 6, 10, 8, 8, 7, 7, 10, 5, 6, 8, … You can see that the number of primes in a block of 100 numbers in the neighborhood of a million hovers around the "expected" value of 100 / log(1,000,000), which is 7.23824, but irregularly. Here we are in the presence of statistical truth.
Same thing in the neighborhood of a trillion, where the "expected" number of primes in a hundred-block would be 100 / log(1,000,000,000,000), which is 3.61912. Starting ten hundred-blocks back from the one I quoted, and going a further ten blocks forward (so the first hundred-block here is from 999,999,998,901 to 999,999,999,000, while the last one is from 1,000,000,000,901 to 1,000,000,001,000), the tallies of primes in each hundred-block are: 2, 1, 3, 6, 3, 2, 6, 4, 2, 5, 4, 4, 6, 2, 4, 2, 4, 3, 5, 1, 6. Again, the tally is hovering around the "expected" value; the average is actually 3.57143. But the hovering is irregular.
To fill this out even more comprehensively, here is a table of the number of primes in the five hundred-blocks before N and the five hundred-blocks after, for N equal to a thousand, a million, a billion, and a trillion. Here you see both the "thinning out" in the distribution of primes, and also the irregularity.
| N | Number of primes in the ten hundred-blocks around N |
Average | 100 / log N | |||
|---|---|---|---|---|---|---|
| one thousand |
14,15,13,15,14,16,12,14,10,17 | 14.0 | 14.476 | |||
| one million |
6,8,6,4,8,6,10,8,8,7 | 7.1 | 7.238 | |||
| one billion |
5,4,6,2,2,7,3,6,3,10 | 4.8 | 4.825 | |||
| one trillion |
6,4,2,5,4,4,6,2,4,2 | 3.9 | 3.619 |
(Incidentally, looking at the lists of numbers in the second column of that table, I am inspired to wonder how big N would have to be before you had a reasonable chance — fifty-fifty, say — of getting a list of ten zeros. A quick back of the envelope calculation, making some primitive assumptions about the statistics involved, suggests that N would need to be around 1046 … but that comes with no guarantees at all!)
* The Fundamental Theorem of Arithmetic
• Reader's point: I have seen it stated that the Euler Product [105.6] is an "analytic version" of the Fundamental Theorem of Arithmetic, which guarantees a unique factorization of an integer into primes. It's not clear to me how this is so. Or how the zeta function would then be related to the Fundamental Theorem of Arithmetic. [Which states: "Any natural number greater than 1 can be represented in exactly one way as a product of primes." For example, the natural number 3,294 is 2 × 33 × 61, and cannot be factorized down to primes in any other way.]
• Author's reply: Well, the Euler Product is the infinite product: (1 − 1/2s)−1 times (1 − 1/3s)−1 times (1 − 1/5s)−1 times … for all the primes 2, 3, 5, 7, 11, 13, … Let's consider just one of those parentheses, the one for prime p. The parenthesis is (1 − 1/ps)−1. Is there some other way to write that? Sure there is. Look at my Expression 9-2 on page 140.9. My parenthesis is just the left-hand side of Expression 9-2, with 1/ps in place of x. I can therefore replace it by the right-hand side of Expression 9-2, which, with x replaced by 1/ps, works out to 1 + 1/ps + 1/p2s + 1/p3s + 1/p4s + …
So now I know that my infinite product, the Euler Product, is equal to (1 + 1/2s + 1/22s + 1/23s + 1/24s + …) times (1 + 1/3s + 1/32s + 1/33s + 1/34s + …) times (1 + 1/5s + 1/52s + 1/53s + 1/54s + …) times (1 + 1/7s + 1/72s + 1/73s + 1/74s + …) times (1 + 1/11s + 1/112s + 1/113s + 1/114s + …) times …
If you survived my Chapter 15, this won't scare you at all. Look at the logic of Chapter 15.iv. To multiply out an infinite number of parentheses, you just
- pluck one element from each parenthesis
- multiply those plucked elements all together
- repeat for all possible plucks, and
- add up the results.
As in Chapter 15.iv, the only plucks you need bother with are those with an infinity of 1's and a finite number of not-1's. This one, for instance:
1 × 1/24s × 1 × 1 × 1/7s × 1/112s × 1 × 1 × 1 × 1 ×
What would that be? It would be 1/(24s × 7s × 112s). The denominator works out to 13,552s.
Now apply the Fundamental Theorem of Arithmetic. It follows that my plucking process will turn up every possible integer exactly once. No other pluck, for example, will give me 13,552. The only pluck that will give me 13,552 is the one I did, because there is no other way to factorize 13,552 into powers of primes! That's the Fundamental Theorem.
So when I come to that last bullet point, "add up all the results," my sum will contain terms like this: 1/ns, with every positive integer n represented exactly once.
So I just proved the Golden Key by plain arithmetic, though I had to know the Fundamental Theorem of Arithmetic to do so. If you want to say that this makes the Golden Key an "analytic version" of the Fundamental Theorem of Arithmetic, I won't argue with you.
* The Necessity of Li(x)
• Reader's point: "Unfortunately, there is no ordinary household function that can be used to express the integral of 1 / log t." [114.0] Hey, if the integral of 1 / x is log x, why isn't the integral of 1 / log t equal to 1 / log(log t))?
• Author's reply: It is! Flip back to page 112.2, where I say: "… read as 'the integral of x to the minus fourth power, with respect to x, from 2 to 3.' (Don't worry too much about that 'with respect to x.' Its purpose is to declare x as the main variable we are working with …)"
Well, here you bump up against the importance of that "with respect to x." The integral of 1 / x with respect to x is log x. The integral of 1 / log t with respect to log t is, indeed, 1 / log(log t)). That's why I said: "It is!" (I should more properly have said: "It might be!" … but allow me a little license for propaganda purposes.)
The integral of 1 / log t with respect to t, however, is Li(t). It matters what you are integrating with respect to. To what you are integrating with respect. With respect to what … aah, the heck with it.
* The Selberg-Erdős Controversy [125.3]
I intended, and thought I made it clear in my book, that I was going to keep this whole business firmly at arm's length, and not get involved. This is a topic that still excites passions. My only contact with it when writing the book, other than having read (and reviewed) the two biographies of Erdős, was a conversation with Atle Selberg in 2002. Selberg was still, 53 years after the event, plainly upset about it.
Since Prime Obsession came out, I have had a number of letters and e-mails about this section. One correspondent took my account of it to be "scathing sarcasm," a description that baffles me. Anyone who thinks that the middle paragraph on page 125 is "scathing sarcasm" just doesn't get out much. I never intended it to be sarcasm of any kind, and remain resolutely neutral on the dispute. My own neutrality, however, need not hinder me in reporting the following simple fact: that most of my correspondents on this matter side with Selberg, notwithstanding the fact that Erdős was plainly liked and admired by just about everybody.
The following, by way of example, is from Professor Emeritus Erik Hemmingsen of Syracuse University, and is reproduced with his permission. Prof. Hemmingsen first points out that while Selberg was indeed at the Institute for Advanced Study when the paper came out, he was actually at Syracuse while doing the work. Prof. Hemmingsen continues:
Selberg was a visitor at the Institute during the academic year 1947-1948, when he came to the attention of one of my colleagues who was also a visitor that year. Syracuse University offered Selberg his first academic job in America, and he and his wife arrived in Syracuse just before the beginning of the Fall 1948 semester. They returned to Princeton in the summer of 1950.
When I arrived at Syracuse in September 1947, Erdős was already there. He was an old friend from the Univ. of Pennsylvania who had a position there when I came as a graduate assistant in 1941. We were both there for several years, and he was very kind to me.
Selberg was naturally pleased when he found his way to a proof of the Prime Number Theorem. The reasonable person to talk to about this work was a kindly older colleague who had a serious interest in number theory. Unfortunately this was a great mistake, so bad [sic] that there are people who credit Erdős with the proof. After Erdős died, there was an article in the Notices of the AMS [i.e. the American Mathematical Society] in which the author went so far as to call the Prime Number Theorem Erdős's finest work. I was totally disgusted and sat myself to write my own impression of the facts. That account is now on deposit with the Syracuse University Mathematics Library.
* The Functional Equation
• Reader's point: Several readers wondered the following thing about the "functional equation" [147.2]: Why doesn't it give ζ(s) = 0 for positive even whole numbers, as well as negative ones? Suppose s is −5, for example. Then the left-hand side of the functional equation is ζ(6), while on the right-hand side I have a term, the sine term, that is zero. So why isn't ζ(6) equal to zero?
• Author's reply: Because of the factorial term on the right-hand side, that's why. As Figure 9-11 shows, the factorial function is "infinite" (that is, it has no defined value) for negative whole numbers. Well, if s is −5, you are multiplying the sine term, which is indeed zero, by (−6)!, which is "infinite." That's why I said, a bit further down the page, "the negative integers create problems …" Those problems can be resolved, but at the level I'm working with here, it is sufficient to assume that when multiplying zero by "infinity," you'll get an actual number, one that is not zero.
* Mathematica's Integrals
• Reader's point: "The integral of 1/(1 − x) is −log(1 − x)." [149.2] Not according to Mathematica, which gives −log(−1 + x).
• Author's reply: Ah, the perils of Mathematica! Actually, I and Mathematica are both right, though my expression makes much more sense in the context, which has x in the range from −1 to +1. Mathematica, of course, cannot know that context.
The thing to remember here is that the derivative of any constant number is zero. So the derivative of x 3 is 3x 2; but so is the derivative of x 3 + 1, x 3 + 2, x 3 + 3, …, x 3 + anything! This makes sense if you think graphically; all those functions have the same graph, but the graph is just shifted up or down vertically … which does not affect the slope of the graph at any argument x.
Contrariwise, when we say that the integral of f(x) is g(x), we should really say (but we hardly ever bother) that the integral of f(x) is g(x) + C, for any constant number C. OK, now rewrite my statement: "the integral of 1/(1 − x) is −log(1 − x) like this:
the integral of 1/(1 − x) is −log(1 − x) + C
Since C can be any arbitrary constant at all, put it equal to −log(−1). By the basic rule of logs, i.e. that log(A) + log(B) = log(A×B), you now get the Mathematica form (because −1 times 1 − x equals −1 + x).
I repeat, though, the Mathematica form is totally unsuitable for the context, in which −log(−1 + x) is a complex number! (As, of course, is −log(−1), whose value is −πi. This "cancels out" the complex numbers Mathematica gives you, so you end up with the actual real numbers I'm actually working with here.)
* 0.123456789101112
• Reader's point: "The number 0.12345678910111213141516171819202 … has a clear pattern, and I could tell you in advance what the hundredth digit is, or the millionth, or the trillionth. (Wanna bet? They are 5, 1, and 1, respectively.)" [172.8] How did you do that?
• Author's reply: By brute force. Let's take the trillionth digit as an example.
It's not to hard to figure out the following scheme:
- The one-digit numbers occupy positions 1 to 9 in the decimal.
- The two-digit numbers occupy positions 10 to 189.
- The three-digit numbers occupy positions 190 to 2,889.
- The four-digit numbers occupy positions 2,890 to 38,889.
- The five-digit numbers occupy positions 38,890 to 488,889.
- The six-digit numbers occupy positions 488,890 to 5,888,889.
- The seven-digit numbers occupy positions 5,888,890 to 68,888,889.
- The eight-digit numbers occupy positions 68,888,890 to 788,888,889.
- The nine-digit numbers occupy positions 788,888,890 to 8,888,888,889.
- The ten-digit numbers occupy positions 8,888,888,890 to 98,888,888,889.
- The eleven-digit numbers occupy positions 98,888,888,890 to 1,088,888,888,889.
So the trillionth position is some digit of an 11-digit number. Which number? Which digit?
Well, the first 11-digit number, which is 10000000000, begins at position 98,888,888,890. Subsequent to that, the 11-digit number 10000000000 + k will begin at position 98,888,888,890 + (11 × k). Now a trillion works out to 98,888,888,890 + (11 × 81,919,191,919) + 1.
Therefore, positions 999,999,999,999 to 1,000,000,000,009 of the decimal contain "91919191919" (10000000000 + 81919191919, see?) It follows that the trillionth digit is 1.
(This is what an amateur-mathematician friend of mine refers to as "breaking rocks." If there is some neat way to get this result, I'd like to know about it.)
* Infinite Sequences
• Reader's point: "… any infinite sequence of numbers in R has a limit in R …" [173.5] Say what?
• Author's reply: That "infinite" should of course read "convergent."
* Figures 13.6 and 13.7
• Reader's point: How did you create Figures 13.6 and 13.7? [213.0, 218.0]
• Author's reply: The only way that came to mind (if you can think of a better one, please let me know!) was to generate a contour map of the following real-valued function of x and y: Re[Zeta[x+y*I]]*Im[Zeta[x+y*I]]. If you do a Mathematica ContourPlot, cramming down the vertical PlotRange to show only values very close to zero (I used PlotRange->{-0.000001,0.000001}), you get a diagram that, with a little hand-trimming, looks like Figure 13.6 or Figure 13.7. Most of my diagrams, by the way, needed some hand-finishing, which was done either by myself or by the patient graphics people at Joseph Henry Press.
* Harold Edwards' book
• Reader's point: In Chapter 13.vii [217.3] you say that you have three copies of Harold Edwards's book Riemann's Zeta Function, but add: "that's a long story." So … what's the story?
• Author's reply: When I was working up the proposal for Prime Obsession, I started reading anything I could find about the Hypothesis, and asking questions of anyone I thought might know something. Time and again I read, or was told: "You simply must get a copy of Harold Edwards's book." So I decided to get a copy. It was long out of print; there had just been the one edition, in 1974. I went on the secondhand book websites. None of them had a copy, but I posted requests to be notified if one turned up. Then I just asked anyone I could think of if they had a copy they could sell me. I asked Harold himself; he was sorry, but he had no spare copies left. I asked his publisher; I asked everybody. No-one had a copy.
In frustration, I went to one of the local universities (Hofstra, I think it was) and persuaded them to let me take out a library copy. Using my desktop scanner at home, I copied the whole book. It took me all day, but at last I had a copy of Riemann's Zeta Function, if only in loose-leaf. I returned the university copy to the library.
No sooner had I got through doing that, of course, than one of those second hand book websites came through with a copy. I bought it; so now I had a copy in loose leaf, and an actual hardcover book.
At the Courant conference in 2002, I met Harold Edwards. He told me that all the enquiries I made about getting a copy of his book had caught the interest of his publisher somehow, and they had decided to bring out a new edition. They had duly done so in 2001, a very nice paperback edition. Would I like one? So I got a copy of the 2001 paperback edition, inscribed by Harold.
* The Minimal Field F2
• Reader's point: You introduce the concept of "field" [266.0] and tell us that a field is formed "if the elements can be added, subtracted, multiplied and divided, according to the ordinary rules of arithmetic … The results of all these operations must stay within the field." So far, so good. Then comes "the simplest of all fields, with only two elements, 0 and 1." In order for the results to "stay within the field" 1 + 1 = 0 and 0 − 1 = 1. How is this consistent with the "ordinary rules of arithmetic"?
• Author's reply: Perhaps I should have spelled out the actual "ordinary rules of arithmetic" I was referring to. They are as follows. In what follows, "number" means "an element of the field."
- Results of arithmetic operations stay within the field. (That one I did mention).
- Some number — always written as "0" (pronounced "zero" in English) — has the following property: a + 0 = a for all numbers a.
- Some number — always written as "1" (pronounced "one") — has the following property: a × 1 = a for all numbers a.
- For every number a there is another (not necessarily different) number, usually written "−a" (pronounced "minus a" or "negative a") for which a + −a = 0.
- For every number a except 0 there is another (not necessarily different) number, usually written either "1/a" (pronounced "1 over a" or "a reciprocal") or "a −1" (pronounced "a to the minus 1") for which a × 1/a = 1.
- For any two numbers a and b (not necessarily different), a + b = b + a.
- For any two numbers a and b (not necessarily different), a × b = b × a.
- For any three numbers a, b, and c (not necessarily all different — and in the case of the minimal 0, 1 field, they can't be!), a + (b + c) = (a + b) + c.
- For any three numbers a, b, and c (same remark), a × (b × c) = (a × b) × c.
- For any three numbers a, b, and c (same remark), a × (b + c) = (a × b) + (a × c).
All of those things are true for the 0, 1 field. For example: 1 × (0 + 1) = (1 × 0) + (1 × 1). Both are equal to 1. The oddity in this field is that "−1" is actually equal to 1. But nothing in the above rules forbids that!
* p-adic Numbers
• Reader's point: You lost me with p-adic numbers. [319.6] Can you give a fuller explanation?
• Author's reply: Well … it's an advanced topic, and you should really read it up (I recommend Fernando Gouvêa's book) or google it. Here is the briefest, simplest possible explanation I can think of.
First, pick an actual prime number, to make things clearer. I'll take p = 5.
Now remember from [97.1] that there is a "clock arithmetic" for any number bigger than 1. On a 12-hour clock, for example, the hours are numbered from 0 to 11. If you add 9 to 7 on this clock (i.e. if you ask the question: "What time will it be 9 hours on from 7 o'clock?") you get 4. So 7 + 9 = 4 in this arithmetic.
Now write out the powers of 5: 51, 52, 53, 54, 55, 56, … These work out to 5, 25, 125, 625, 3125, 15625, …
Now, giving one line to each, write out, first, all the hours on a 5-hour clock-face; then all the hours on a 25-hour clock-face; then all the hours on a 125-hour clock-face; and so on. Like this:
0, 1, 2, 3, 4
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …, …, 20, 21, 22, 23, 24
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …, …, 121, 122, 123, 124
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …, …, 621, 622, 623, 624
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …, …, 3121, 3122, 3123, 3124
…, …
(The list goes on for ever.)
Now pick a number at random from that first row. I'll pick 3.
Now pick a matching number at random from the second row. By "matching," I mean this: the number has to leave remainder 3 after division by 5. So you can pick from 3, 8, 13, 18, and 23. I'll pick 8.
Now pick a matching number at random from the third row. By "matching," I mean this: the number has to leave remainder 8 after division by 25. So you can pick from 8, 33, 58, 83, and 108. I'll pick 58.
Now pick a matching number at random from the fourth row. By "matching," I mean this: the number has to leave remainder 58 after division by 125. So you can pick from 58, 183, 308, 433, and 558. I'll pick 183.
Now pick a matching number at random from the fifth row. By "matching," I mean this: the number has to leave remainder 183 after division by 625. So you can pick from 183, 808, 1433, 2058, and 2683. I'll pick 2683.
Keep going … for ever.
You now have a sequence of numbers, which I'll pack together into a neat parenthesis and call x. Here it is:
x = (3, 8, 58, 183, 2683, …)
That is an example of a 5-adic integer. Note "integer," not "number." I'll get to "number" in a minute.
(Obviously you could do this for any prime p. I'm just using 5 as an example.)
Here's another 5-adic integer:
y = (0, 20, 95, 95, 1970, …)
Now, you can add these numbers together:
x + y = (3, 3, 28, 278, 1528, …)
See how I did that? I just added according to the appropriate clock arithmetic in each position: 5-hour in the first position, 25-hour in the second, and so on. Notice that the result is another 5-adic integer, with each number in the correct relation to the number on its left.
You can not only add: you can subtract and multiply, too. You can't necessarily divide, though. This sounds a bit like the regular integers, which you can likewise add, subtract, and multiply, but not always divide. (12 ÷ 7 = not an integer). It is what mathematicians call a ring. This is the ring of 5-adic integers. Its usual symbol is Z5. (That should be the "hollow Z" that I introduced in Chapter 11, but I don't have it in my symbol set here.)
How many 5-adic integers are there? Well, in populating that first position you had a choice of five. Same for the second position, same for the third, … So the number of possibilities altogether is 5∞. What other set has this number? Well, consider all the real numbers between 0 and 1, and represent them in base 5 instead of the usual base 10. Here is the fraction 1/π, for example, written in base 5: 0.1243432434442342413234230322004230103420024 … Obviously, each position of this "decimal" (I suppose that should be something like "quinquimal") can be populated in five ways. Just like our 5-adic integers! So the number of 5-adic integers is the same as the number of real numbers between 0 and 1.
This is an interesting thing. Here we have created a ring of numbers that behave like the integers; yet they are as numerous as the real numbers! (The ordinary integers are not that numerous. Google on "transfinite numbers" if you don't know about that.) And in fact, there is a way to define the "distance" between two 5-adic integers in a natural way; and it turns out that two 5-adic integers can be as close together as you please — entirely unlike the ordinary integers, two of which can never be separated by less than 1.
So these 5-adic integers are kind of like the integers, and kind of like real numbers.
Now, just as with the ordinary integers Z, you can go ahead and define a "fraction field" Q — the rational numbers — so with Z5 there is a way to define a fraction field Q5 in which you can not only add, subtract and multiply, but also divide. That is the field of 5-adic numbers.
Q5, like Z5, has a foot in each camp. In some respects it behaves like Q, the rational numbers; in others, it behaves like R, the real numbers. Like R, for instance, but unlike Q it is complete [173.6].
That's about as much as I can say about p-adic numbers in a way that's elementary. I hope you can see, at least, that they are curious and interesting little creatures.
Now, just as, starting from ordinary "clock" arithmetic, I went up one level of abstraction and got these peculiar p-adic numbers; so, by going up a further level of abstraction, starting from p-adic numbers, you can get adeles. I'm not going to attempt it here, but you can read up the topic in plenty of textbooks and websites.
[Note that there are a number of different ways to approach p-adic numbers. If you go and read about them in a textbook or on a website, the author might take an utterly different approach to this one. Trust me, the destination is the same!]
* That Entire Function
• Reader's point: What's that entire function you talk about at 333.1? What does it look like?
• Author's reply: Like this:
ξ(s) = (s / 2)! × π(−s/2) × (s − 1) × ζ(s)
Note the right-hand side has four parts. If you flip it round to show ζ(s) in terms of ξ(s), that has four parts, too, obviously. This is why Expression 21.1 [328.2] has four parts. ξ is an entire function. Its zeros are precisely the non-trivial zeros of the ζ function; that follows easily from the definition. And it can be written in terms of those zeros, as ξ(0) times all possible (1 − s/ρ), for all the zeros ρ Full details are in Chapter 1 of Harold Edwards's book on the zeta function, which I can't recommend highly enough. See also the closing remarks here
* Those Secondary Terms in Table 21-1
• Reader's point: Were the "Secondary term" figures in Table 21-1 [344.3] actually calculated by summing Li(1000000ρ)?
• Author's reply: No. Trusting Riemann's formula (which has, after all, been proved true) I reverse-engineered them. However, I spot-checked by summing across the first 100,000 of Andrew Odlyzko's zeros (which are on his website) and eyeballing the sums to 10,000, 20,000, 30,000, … 100,000, to satisfy myself that convergence was what I expected. The problem here, as I point out [342.7], is that convergence is "harmonic." That is, it is logarithmically slow, like the convergence of Expression 9-4 [149.7]. Even summing to 100,000 terms does not necessarily get you four decimal places of accuracy. I trusted Riemann and von Mangoldt (who proved Riemann's formula), and checked only to make sure I had not misunderstood them.
* The Formula for J(x)
• Reader's point: I'm not clear about the role of the Hypothesis in Chapter 21 [349.1]. Does the formula for J(x) (Expression 21-1 [328.3]) depend on the Hypothesis being true?
• Author's reply: No. To my mind, this is a serious weakness in my exposition, and I wish I had made it more clear. Riemann's formula (Expression 21-1) does not depend on the truth of the Hypothesis. The formula is absolutely, indisputably true — Von Mangoldt proved that. There is a proof in Harold Edwards' book Riemann's Zeta Function.
That formula is the main result of Riemann's 1859 paper. It was that formula he was heading for through the paper. As he said, and as I quoted (twice: [x.1], [151.9]), he "put aside the search for such a proof … because it is not necessary for the immediate objective of my investigation." That "immediate objective" was my Expression 21-1. It does not need the RH.
The great importance of Riemann's formula is that it uncovers the intimate link between (a) the distribution of the primes, and (b) the zeros of the ζ function. It tells us: If you want to know about the distribution of the primes, all the facts are buried away there in the zeros of the ζ function.
If you then start to ask questions about the actual nature of the distribution — especially "big oh" questions about the size of the error term in the Prime Number Theorem π(N) ∼ Li(N) — then the RH comes into play, since it lets you get the most precise possible results about the distribution of the primes. If the RH is not true, then the best results you can get will be less precise. That formula, however, is true in either case.
* Endnote 10
• Reader's point: Where did you get the result in Endnote 10 [366.9]? Can you prove it?
• Author's reply: I've been carrying it round in my head since college days. I suppose one of my instructors must have mentioned it. Here is a heuristic argument. You can find the full deal in the London Mathematical Gazette, Vol. 74, No. 768 (June 1990), pp. 167-9, "Another surprising appearance of e," by Nick Mackinnon and 5Ma (? no idea) of Winchester College. Since I heard it in my college days (way before 1990), this can't be the first appearance of this result. There must be an earlier one.
Heuristic argument To get started, ask: What's the probability that the sum of just two random numbers exceeds 1? Well, it's the probability that a point in the unit square, whose corners are at (0,0), (0,1), (1,0), and (1,1), satisfied the inequality x + y ≥ 1. This is of course 1/2: just draw the diagonal from (0,1) to (1,0), and it's the probability that (x,y) is in the upper right triangle, which is half the area of the square.
If you now go to three random numbers, the chance that their sum exceeds 1 is got by "cutting a slice" across the unit cube with corners at (0,0,0), (0,0,1), (0,1,0), (0,1,1), (1,0,0), (1,0,1), (1,1,0), (1,1,1). The slice goes through the corners (1,0,0), (0,1,0), and (0,0,1). This slices off a pyramid, volume 1/6, and the probability x + y + z ≥ 1 is then 5/6.
A little mild calculus, plus the principle of induction, easily shows that the super-pyramid sliced off an n-dimensional super-cube by a hyper-plane through its corners (1,0,0,0, …), (0,1,0,0, …), (0,0,1,0, …), … has volume 1/(n!)
The probability that a total of 1 is exceeded after adding n random numbers is therefore 1 − 1/(n!)
The probability that a total of 1 is exceeded after adding n random numbers but not before is therefore (1 − 1/(n!)) − (1 − 1/(n − 1)!), which simplifies to (n − 1) / (n!)
The expected number of selections until a total of 1 is exceeded is therefore the sum, from n = 2 to infinity, of n × (n − 1) / (n!), which is e.
You can also compute the variance, which turns out to be 3e − e 2.
* Endnote 28
• Reader's point: "Take three positive whole numbers at random …" [371.5] Huh? From what probability distribution?
• Author's reply: Yeah, yeah. There is no neat way to say this in the space of an endnote, for the readership I was aiming at. You can fill out the details. "Let N and K be large positive integers, and consider a uniform distribution across the range from N to N + K …"
* ExpIntegralEi
• Reader's point: What is this ExpIntegralEi function in Endnote 128 [390.3]? What's it got to do with the Li function?
• Author's reply: It's one of the lesser-known functions of analysis, written in textbooks as "Ei(x)" and called "the exponential integral function."
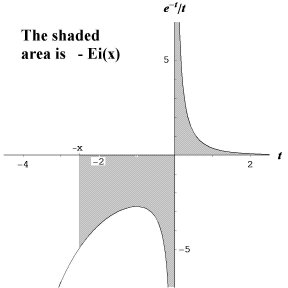
For real arguments, it is defined as minus one times the integral, from minus x to plus infinity, of e −t / t (with some Figure 7-4-type fudging to let you integrate across the value t = 0).
It is quite important in integration because any function of the form R(x) e x, where R(x) is a rational function (the ratio, that is, of two polynomials, like the functions on [269]) has an integral that is a combination of ordinary functions and Ei.
Now, if you take the ordinary definition of Li(x) (which is: the integral from zero to x of 1 / log t) and do a couple of elementary substitutions (u = log t, then v = −u), you get Li(x) = Ei(log x).
In the complex realm things are nastier. You need to define both Li(z) and Ei(z) by analytic continuation (a sort of analogy to the "domain stretching" I did in Chapter 9). It turns out that in doing this you are presented with options as to how, precisely, you want to define the function (analogous — I'm sorry about the analogies, but this is tough math here — to the options for Li(x) in the real realm that I mentioned in Endnote 37 [373.6]). Well, the options the Mathematica coders took when they defined the Mathematica LogIntegral function for complex arguments did not accord with Riemann's use of this function in his paper. Once I realized this, knowing the formula Li(x) = Ei(log x), I tried the Mathematica function ExpIntegralEi[Log[z]]. Sure enough, Mathematica had defined their ExpIntegralEi function in such a way that ExpIntegralEi[Log[z]] gives just the right values for Riemann's interpretation of Li(z) in the complex realm. So that's what I used.
In the complex realm, it is a fact about the Ei function that if you hold the real part of the argument fixed and let the imaginary part go off to infinity (in other words, if you compute Ei(a + bi) for some fixed a and ever more humongous values of b), the function value closes in on πi. Since log x goes off to infinity (albeit achingly slowly) when x does, it shouldn't be hard to believe that the same applies to Li(a + bi). Which is why those spirals in Chapter 21 [347] close in on πi and −πi.
I don't have a textbook that gives a full account of the Li and Ei functions for complex arguments, but I shall try to find one and recommend it. (Or, if you know one, please email and tell me!)
There is, incidentally, a very nice and fast-converging series expansion for Ei(t) when t is positive. Here it is:
Ei(t) = γ + log t + t + t 2 / (2 × 2!) + t 3 / (3 × 3!) + t 4 / (4 × 4!) + …
where γ is the Euler-Mascheroni constant (Endnote 19 [369.9]), equal to 0.577215664901532860606512 … I don't know of any neat series for Li(t), though. Speaking very generally, log and the related functions are not series-friendly.
* The Claims of Louis de Branges
• Reader's point: Numerous readers have asked me about Louis de Branges' supposed proof of the RH, which got some publicity in mid-2004. As a follow-up in the newspapers, there was some discussion about e-commerce being undermined if Louis' proof was sound. Here is my take on the whole business.
• Author's reply: (1) I consider it highly unlikely that de Branges has cracked the RH, and this opinion is widely shared. De Branges is a bit of a joker & this looks like one of his old tricks. The only reason mathematicians do not laugh out loud at him is that he did once, after a similar record of crying "Wolf!" produce an actual wolf: his 1984 proof of the Bieberbach [383.6] Conjecture. However, Louis' paper is being scrutinized by mathematicians, and a decisive verdict will come in in the next few months.
(2) A resolution of the RH (i.e. a watertight proof that it is either true, or not true) would, so far as I can see, have no direct impact on e-commerce. The main encryption method used for e-commerce, called "RSA," depends on the following fact: If I tell you that a large number N is the product of two large primes P and Q, and invite you to find out what the values of P and Q are, you can't. Not, at any rate, without using geological eons-worth of computer time. (I am over-simplifying here, but this is the essence of it. For a fuller account, see note 6.5 on this page.)
In short, if a number is the product of two humongous primes, it is really, really difficult to factorize it. If you could find a quick'n'easy way to factorize such big products, you'd be able to decrypt RSA-coded messages.
The RH is, at a very deep level, a statement about prime numbers. The idea is, that if we resolve the RH, we shall thereby know much more about prime numbers, and may have a quick way to factorize these huge products, making RSA untenable.
I don't see this. The typical prime used in RSA has 70 or so digits; the primes affected by a resolution of RH are at a far higher level — bazillions of digits. Down in the comparatively "small number" zone where RSA works, the RH is to all intents and purposes true.
There is, in fact, a school of thought that says the RH is not really "about" prime numbers at all, that its consequences for the distribution of primes are in a strong sense "incidental." Prof. Harold Edwards is of this mind. His review of Prime Obsession and two other books on the RH (The Mathematical Intelligencer, Winter 2004, Vol. 26, No. 1) concludes with this thought:
A parting thought. In my opinion, all three books grossly overstate the connection of RH to prime numbers. Derbyshire even chooses the title Prime Obsession. True, an investigation of the distribution of primes and the Euler product formula led Riemann to RH, but Riemann himself quickly switched to another function he called ξ(t) … and his actual hypothesis was that the zeros of ξ(t) are real! To me, ξ(t) is a symmetrized version of ζ(s) — symmetrized to put the functional equation of ζ(s) in a simple form and to put the interesting part of the function on the real axis — that is an entire function of one complex variable. RH is simply the statement that its zeros are real. The connection with prime numbers may or may not play a role in explaining the amazing extent to which Riemann's hunch has been borne out by massive modem computations unimaginable in his day. Despite this modem evidence in its favor, and despite its connection to a raft of fascinating and theoretically important "generalized Riemann hypotheses" that also stand up to computational scrutiny, no one seems to have any idea why it should be true.
(In self-defense, I should say that I did not choose Prime Obsession as my title. That was my publisher's work.)
In any case, these news stories seem to be based on nothing more than the following glib, but false, syllogism:
• RSA cryptography is about primes.
• The RH is about primes.
——————————————
• If the RH is cracked, RSA is in trouble!
… Although I'd like to add this: if anyone cracks the RH, it will probably be by dint of some radically new ideas in analytic number theory. (Since the old ones have all been tried!) Those new ideas might have wider application, and just possibly might lead us to new methods of factorizing big numbers. But that would be a fortuitous and indirect effect of an RH resolution, not a necessary one.
* The Sign of the Sine of p
• Reader's point: Starting from the "easternmost" point of the unit circle, proceed counterclockwise round the circumference a distance p, where p is some prime number. (Equivalently: Mark an angle of p radians.)
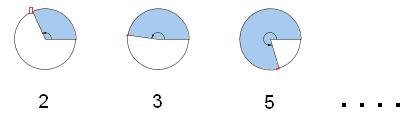
You are now either above or below the x-axis. (That is, the sine of p radians is either positive or negative.) Can anything be said about how often you are above, how often below?
• Author's reply: Well, there might be a Chebyshev bias there! [125.9] Let's see.
I just ran a program to take each prime p in turn from 2 to 100,711,433 (which is all the primes I have handy), divide p by π, and mark the result "P" (for "positive") or "N" (for "negative") according as the integer part is even or odd, respectively. For the first seventeen primes this gives me PPNPNPNPNNNNNNPPP.
If I tally the Ps and the Ns, computing P − N (I mean of course the count-of-Ps-so-far minus the count-of-Ns-so-far) for each prime, I get positive numbers up to p = 29. Then at p = 31, P − N flips to negative. It stays negative until p = 97; then at p = 101 it flips back to positive, … and so on. The first few "flip primes" are actually 31, 101, 167, 229, 269, 271, 307, 311, 313, 317, 331, 359, 439, 479, 487, 491, 691, 787, 797, 3739, 3761, 3821, …
Look at that run — it's a run of negatives — from 797 to 3739. It prefigures much longer runs further along in the primes. There's a flip to negative at 7,697,993, for example; then P − N stays negative all the way to the next flip at 72,277,813.
Again, after a flip to negative at 76,996,169, the value of P − N stays negative until I run out of primes at 100,711,433. (At which point P − N is a robust −5,966.)
It sure looks like there are some Chebyshev-type biases in play there, though without an understanding of the underlying statistics, I wouldn't make a definite pronouncement … Interesting that the really big runs tend negative; the biggest run of positive P − N in my range is from 1,291,673 to 4,411,679.
* The Series for Zeta Doesn't Work when s ≤ 1
• Reader's point: If s is a negative integer, the series for ζ can't converge. If s = −2, for example, the series is 1 + 4 + 9 + 16 + 25 … No way that converges!
• Author's reply: This one is very vexing to me, but I've included it because I have been asked about it by so many readers.
The reason it's vexing to me is that I pointed it out myself in Chapter 5.ix, then gave over the whole of Chapter 9 to resolving the problem! Obviously I didn't do a good enough job, but I'm stuck to think of anything else I might have done.
The heart of the matter is at the end of Chapter 9.iii:
The moral of the story is that an infinite series might define only part of a function; or, to put it in proper mathematical terms, an infinite series may define a function over only part of its domain. The rest of the function might be lurking away somewhere, waiting to be discovered by some trick like the one I did with S(x).
That function S(x), which I start off defining by means of an infinite series at the beginning of Chapter 9.ii, suffers from the same defect as ζ: the series only works when x is in a certain range (between −1 and +1). Outside that range the series doesn't work but the function it represents still exists.
I show this in Chapter 9.ii by pulling a neat trick with S(x), showing that my infinite series represents part of the function 1 / (1 − x). There's a similar trick (it has a name: "analytic continuation") for ζ, but my handicap here is that it's too hard to explain in a book at this level. I just hoped to show the reader it could be done, by analogy to S(x).
* Denjoy's Probabilistic Interpretation Revisited
• Reader's point: This comes from Harry Barrow, recently retired from 35 years' research in Computer Science and Artificial Intelligence over in Cambridge, England.
One thing that intrigued me in your book was Denjoy's Probabilistic Interpretation, in particular your statement: "To put it another way, it says that a square-free number is either a "head" or a "tail" — has either an even or odd number of prime factors — with 50-50 probability. This does not seem particularly unlikely and might in fact be true. If you can prove that is is true, you will have proved the RH."
If we consider the set of square-free numbers with highest prime factor less than or equal to a chosen prime, p, then it is easy to show that exactly half of them have an odd number of factors, and half even. As we step through the primes p this is always true, no matter how large p becomes. See this pdf file for a proof.
Unfortunately, I suspect the link to the RH may be more tricky than you suggest … Theorem 15-2 concerning Mertens' function might not be exactly equivalent to the 50-50 ratio, and relating my proof to Theorem 15-2 raises interesting questions. Consequently, I doubt that we have found the missing link in the proof of the RH!
• Author's reply: It was too good to be true, I guess. But I'm going to take a close look and blog further …
—————————